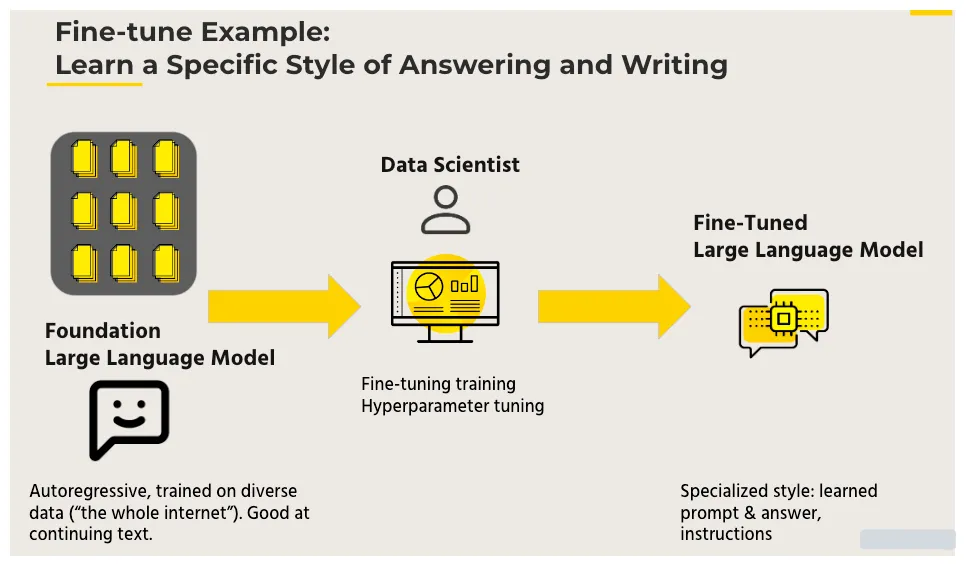
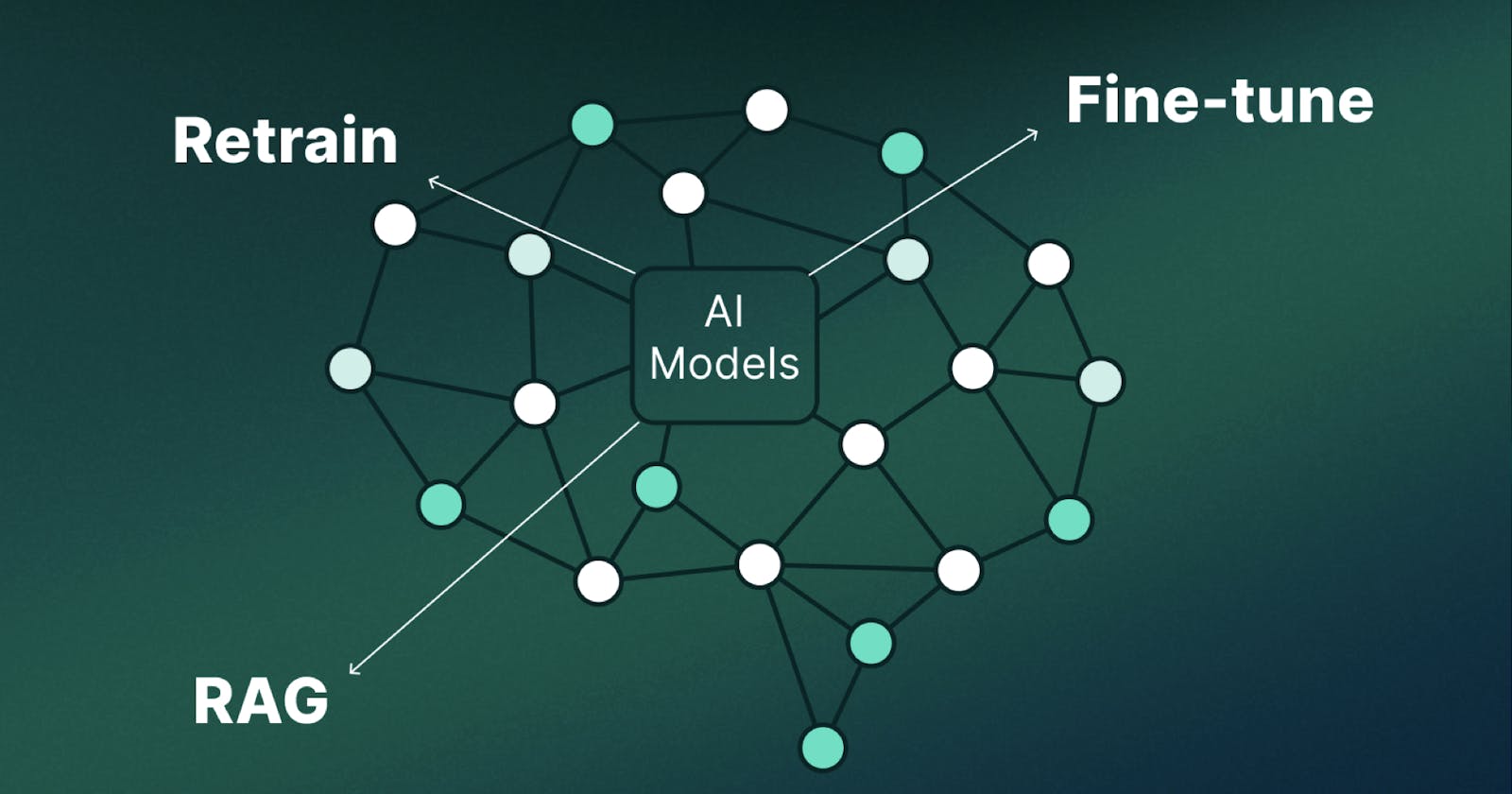
The LLM Triad: Tune, Prompt, Reward - Gradient Flow
4.7 (284) · $ 28.99 · In stock

As language models become increasingly common, it becomes crucial to employ a broad set of strategies and tools in order to fully unlock their potential. Foremost among these strategies is prompt engineering, which involves the careful selection and arrangement of words within a prompt or query in order to guide the model towards producing theContinue reading "The LLM Triad: Tune, Prompt, Reward"

Open-Source LLM Explained: A Beginner's Journey Through Large Language Models, by ByFintech @ AI4Finance Foundation

Retrieval-Augmented Generation for Large Language Models A Survey, PDF, Information Retrieval

Reinforcement Learning from Human Feedback (RLHF), by kanika adik
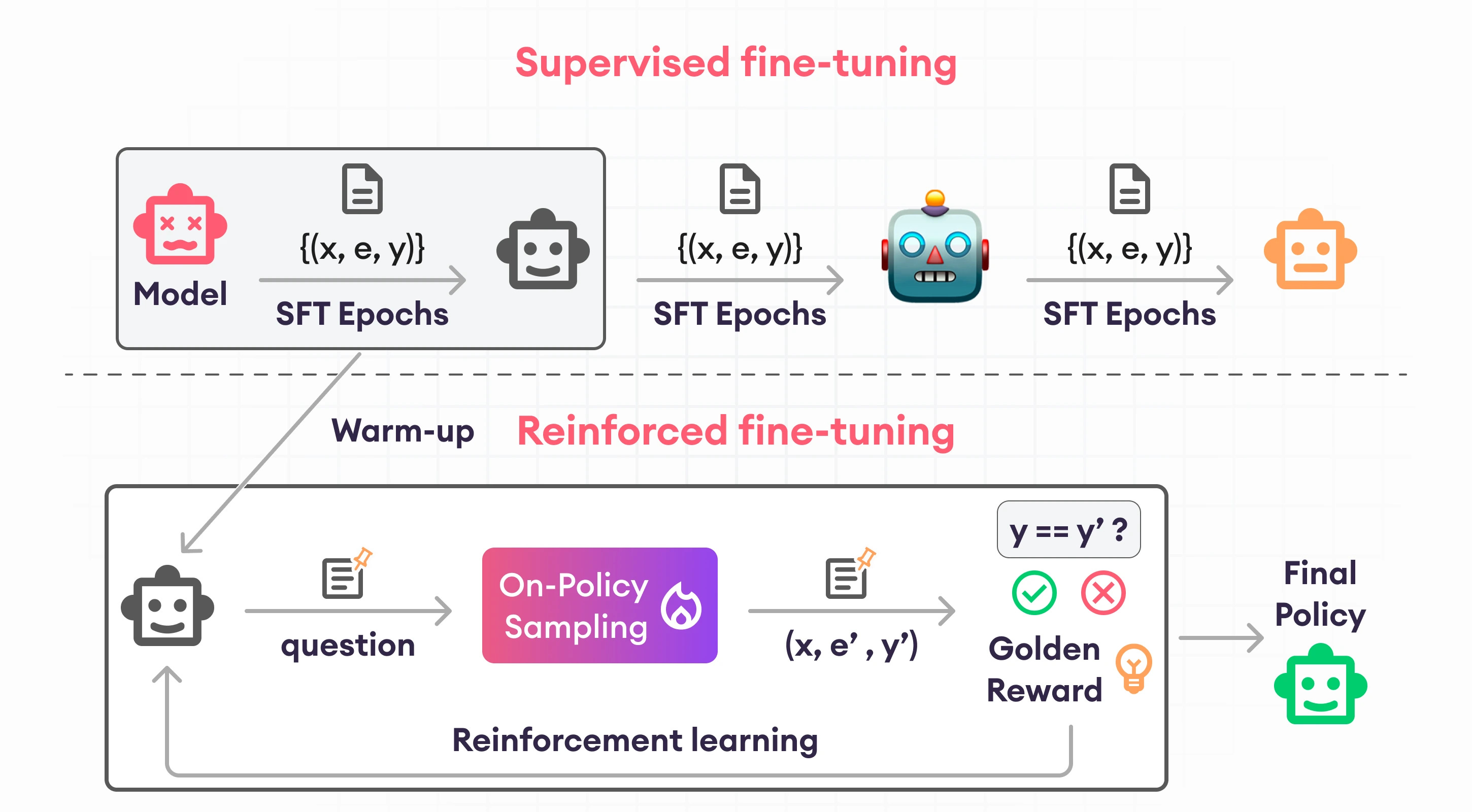
Edge 377: LLM Reasoning with Reinforced Fine-Tuning
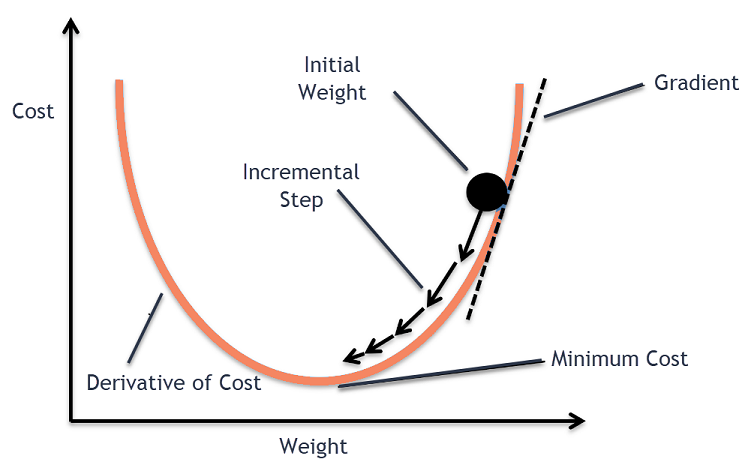
Demystifying Large Language Models for Everyone: Fine-Tuning Your Own LLM. Part 1/3, by Jair Neto

Gradient Flow
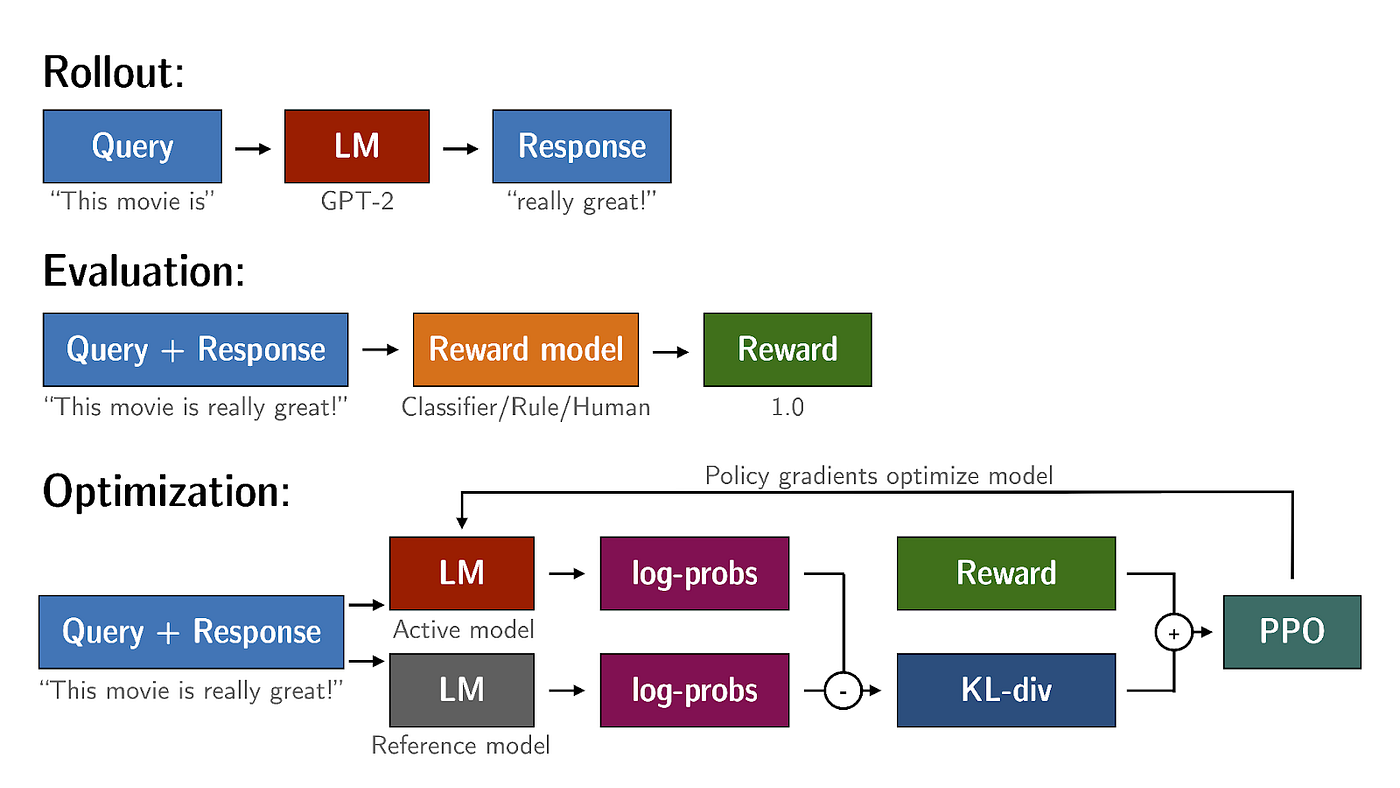
Finetuning an LLM: RLHF and alternatives (Part II)

Retrieval-Augmented Generation for Large Language Models A Survey, PDF, Information Retrieval
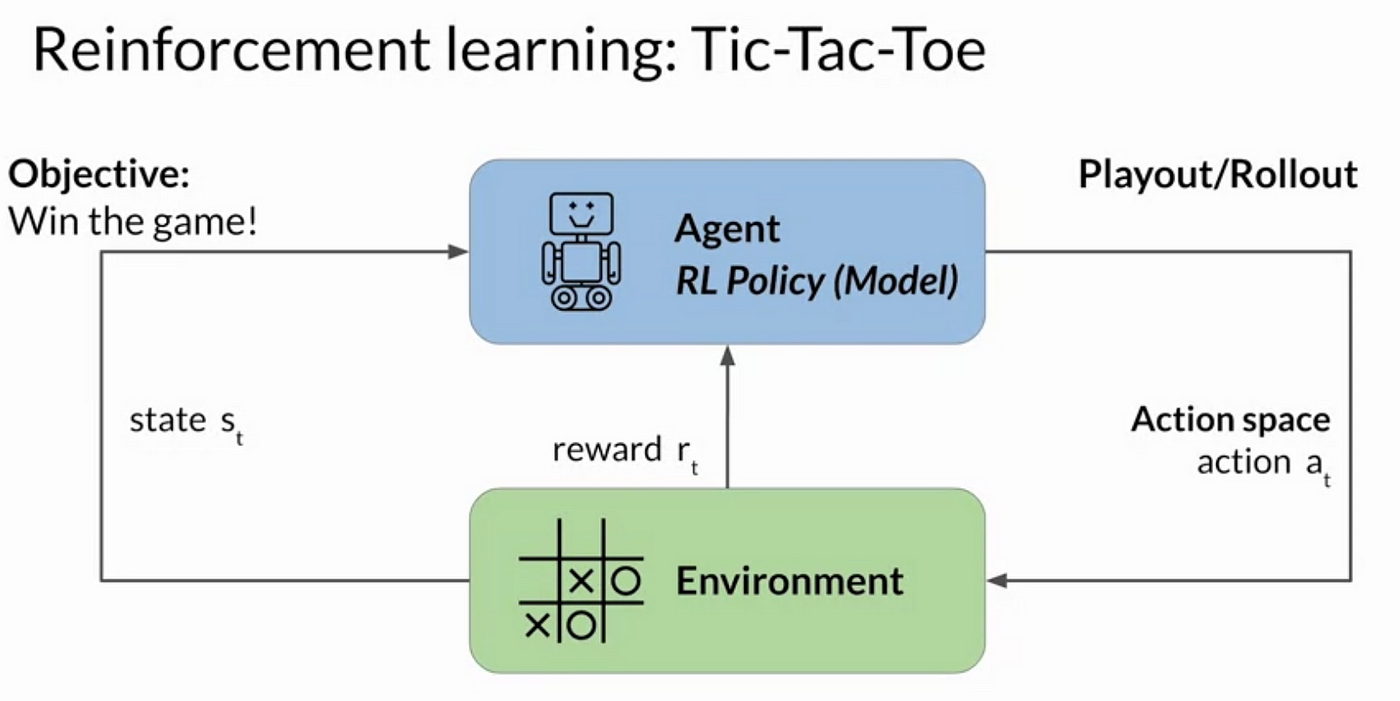
Reinforcement Learning from Human Feedback (RLHF), by kanika adik
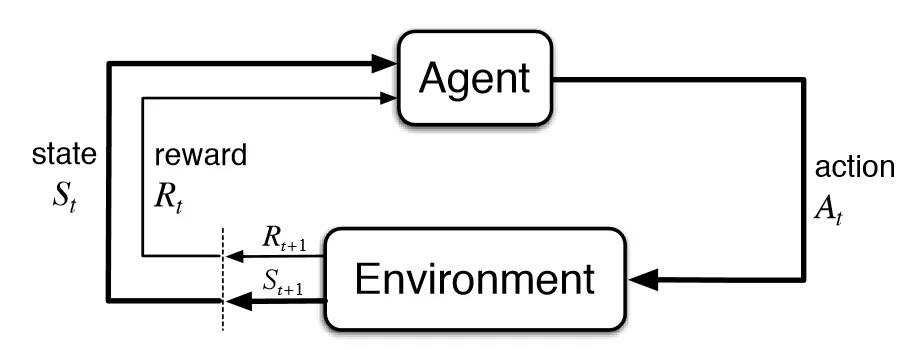
Understanding RLHF for LLMs

The LLM Triad: Tune, Prompt, Reward - Gradient Flow

Some Core Principles of Large Language Model (LLM) Tuning, by Subrata Goswami

Gradient Flow

Paper page - Directly Fine-Tuning Diffusion Models on Differentiable Rewards
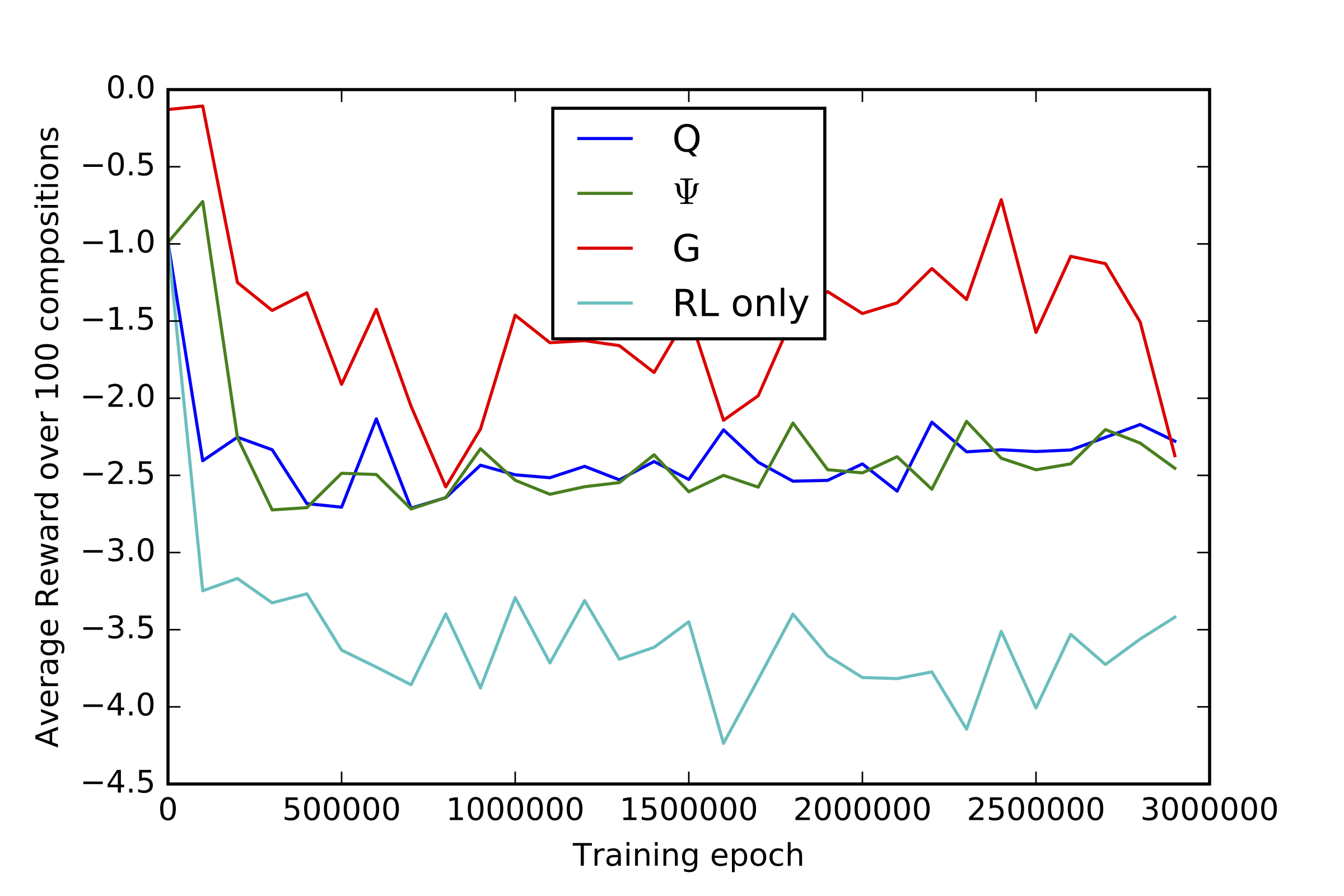
Tuning Recurrent Neural Networks with Reinforcement Learning





/stickers-very-sexy-young-beautiful-ass-in-thong-at-the-gym-club.jpg.jpg)