Language models might be able to self-correct biases—if you ask them
4.5 (767) · $ 24.00 · In stock

A study from AI lab Anthropic shows how simple natural-language instructions can steer large language models to produce less toxic content.

$25-$45/hr Mit Technology Review Jobs (NOW HIRING) Mar 2024

Self-Correction of Biases in Language Models -Lit Review
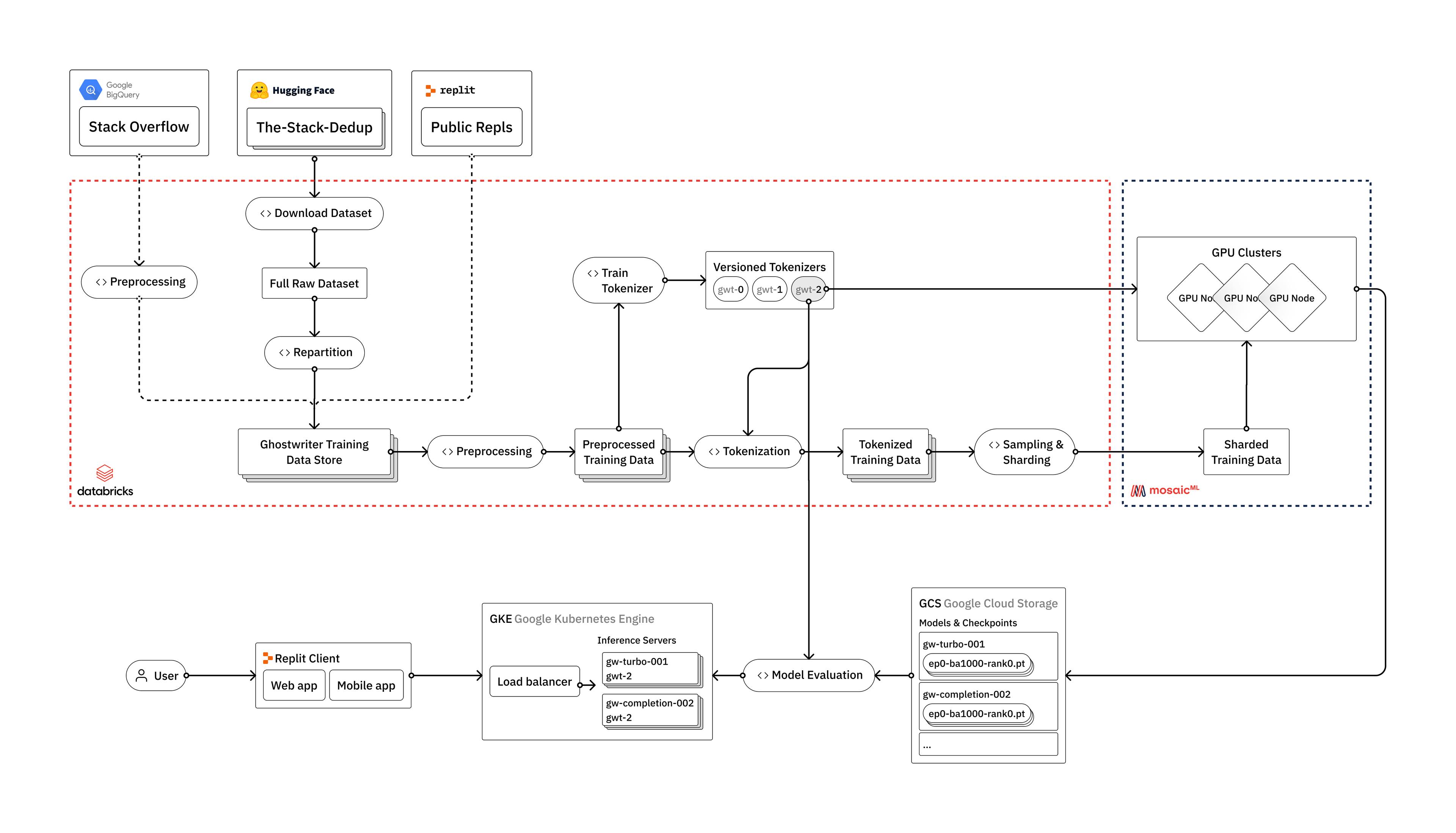
Replit — How to train your own Large Language Models

9 Actionable Tips To Avoid AI Detection In Writing

Language models might be able to self-correct biases—if you ask

Simon Porter on LinkedIn: Language models might be able to self

Articles by A.W. Ohlheiser

What Are Large Language Models (LLMs)?

The Dark Side of Large Language Models
You may also like






Related products





© 2018-2024, stofnunsigurbjorns.is, Inc. or its affiliates